Olá pessoal! Chegamos ao capítulo 3 da certificação que fala sobre WCF, a tecnologia primária da Microsoft para o desenvolvimento de aplicações SOA. Esse é o componente com mais conteúdo na certificação e que tem o maior número de objetivos (9).
O primeiro objetivo, Create a WCF service, é a introdução ao assunto e um dos maiores objetivos da certificação. Esse objetivo fala sobre conceitos de SOA, como criar contratos, implementar Message Inspectors e operações assíncronas no serviço.
Conceitos de SOA
Antes de entrar na discussão sobre como construir ou manter serviços, alguns componente de SOA precisam ser definidos. São eles:
- Service: um componente que é capaz de fazer uma ou mais tarefas;
- Service definition: um contrato que define uma feature do serviço. O uso de contratos é uma característica determinante de SOA.
- Binding: item que especifica o transporte, encoding e detalhes do protocolo necessários para se realizar uma conexão cliente-servidor;
- Serialization: Como SOA envolve comunicação entre diferentes processos, a serialização é necessária para que os dados sejam transferidos e consumidos entre esses processos.
Alguns conceitos universais de SOA são também importantes:
- Fronteiras são explícitas: para se comunicar com um serviço, você precisa saber algumas coisas dele. Qual é o ponto de entrada do serviço? Quais operações ele suporta? Quais mecanismos de comunicação são aceitas?
- Serviços são autônomos: o serviço e quaisquer dependências devem ser independentemente deployados, versionados e configurados;
- Serviços compartilham schemas e contratos, não classes: para se comunicar com um serviço, o client precisa saber a URI, o protocolo de comunicação e quais operações são suportadas. Não é necessária uma cópia das classes ou biblioteca que provê as operações;
- A compatibilidade de serviços é baseada na política: apesar da WSDL (Web Service Definition Language) prover bastante informação sobre o serviço, é impossível informar todos os requisitos que um serviço pode ter.
Criando Contratos
Como visto acima, um elemento crítico de um serviço SOA é o contrato, para que clients e servers possam se comunicar de forma flexível. Há vários atributos que definem o contrato de um serviço WCF, sendo eles:
- Atributo ServiceContract: é o que de fato faz um tipo em .NET se tornar um serviço WCF. Sem ServiceContract, não há serviço;
- Atributo OperationContract: marca uma função como uma operação de um serviço;
- Atributo DataContract: informa ao runtime que o tipo é serializável;
- Atributo FaultContract: provê informações de exceptions de uma forma universal.
Criando Um Projeto WCF
Um serviço WCF é basicamente um compilado de classes. Você pode criar um projeto comum, adicionar algumas referências, definir o contrato com os atributos acima e pronto; temos um serviço WCF. Outra forma, mais recomendada, é criar um projeto WCF diretamente no Visual Studio, que vai adicionar as referências necessárias e construir a aplicação de host (com os bindings e muitas configurações feitas por padrão).
Fazendo pelo Visual Studio, você tem as seguintes opções:
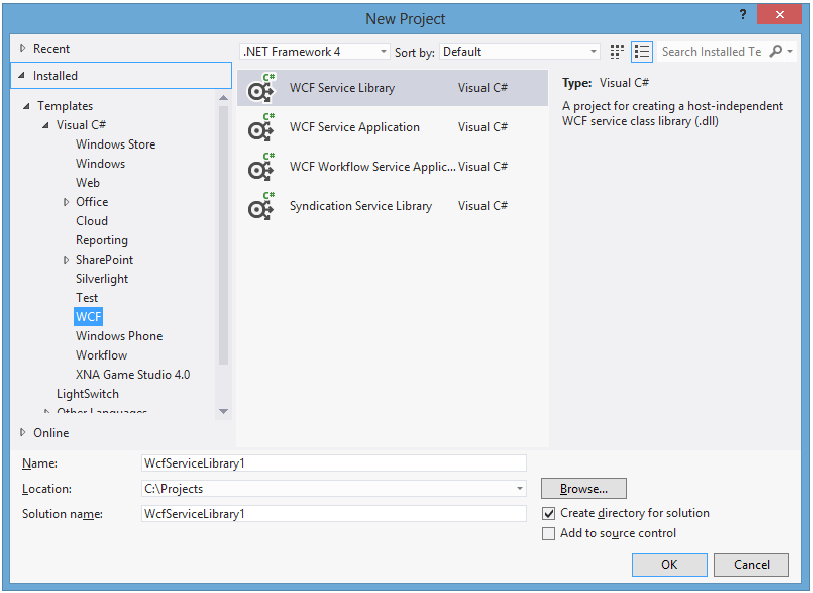
As duas opções mais comuns são WCF Service Library e WCF Service Application. A principal diferença entre elas é que WCF Service Library permite que você crie um serviço independente de hospedagem. WCF Service Application inclui um host IIS ou WAS (Windows Activation Service).
Criando um WCF Service Library, o Visual Studio criará um projeto com as referências necessárias, uma classe de serviço e uma interface de serviço com os atributos ServiceContract e OperationContract. Isso é o básico para que um assembly se torne um serviço WCF.
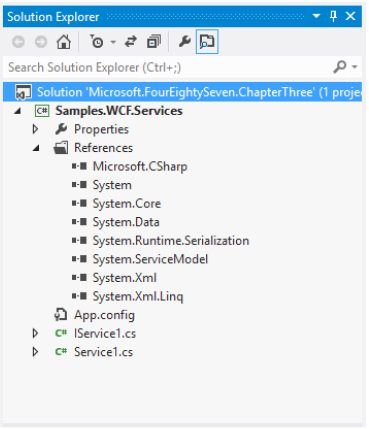
Note as referências à System.Runtime.Serialization e System.ServiceModel, além do arquivo App.config com as configurações do serviço (detalhes em outros objetivos).
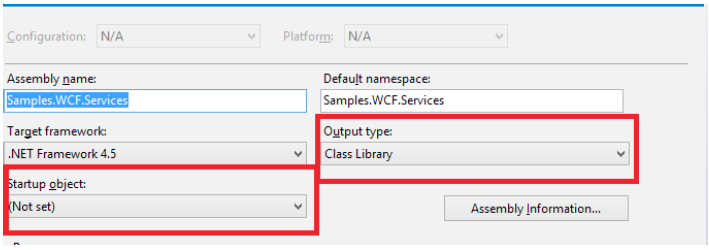
Os dois itens de distinção são que o Output type é definido como class library, reforçando que um serviço WCF é como um assembly normal, e que Startup project não é definido pois é possível ter vários serviços em uma solution, e todos eles são independentes.
Definindo O Serviço
Como visto acima, ao se criar um projeto WCF, o Visual Studio cria por padrão uma interface que define o contrato e uma classe que faz a implementação do serviço. A interface deve ser marcada com o atributo ServiceContract, enquanto os métodos devem ter o atributo OperationContract. É possível ter os atributos diretamente na classe que faz a implementação, mas como a classe vai herdar da interface, faz sentido deixar tudo lá (além de facilitar o reuso e desacoplar o contrato da implementação). Para usar tipos complexos, as classes precisam ter o atributo DataContract. Vamos ao código:
Endpoints
Endpoints são essenciais para um serviço WCF, já que a principal característica de um serviço WCF é a exposição dos dados para vários clientes. O termo “ABC” é frequentemente usado na literatura sobre WCF, que significa:
- A: significa “address”, geralmente uma URI;
- B: significa “binding”, que define como o transporte dos dados será feito. Bindings são definidos para cada serviço, e um serviço pode ser exposto por vários bindings ao mesmo tempo;
- C: “contrato”, a interface definida no serviço.
A lista completa dos bindings (que contém vários métodos para HTTP, TCP, etc.) está disponível em http://msdn.microsoft.com/en-us/library/ms730879.aspx.
Pipeline De Processamento WCF
No consumo de um serviço WCF, você sabe que de um lado há um serviço exposto, e do outro lado um client consumindo. Mas o que acontece entre esses processos?
Direta ou indiretamente, uma classe proxy é criada para o client, e essa classe o habilita a interagir com os métodos do serviço. O request é serializado e transferido pelo protocolo definido no binding. Todas as informações precisam ser desserializadas para o serviço consumir, e vice-versa.
Esse processo de serialização e desserialização precisa ser independente de plataforma, já que o serviço pode ser consumido de qualquer linguagem. Por exemplo, uma aplicação Java ou Python não sabe o que é a classe System.Data.SqlClient.SqlDataAdapter. Arrays, pilhas e filas são conhecidas pela maioria das linguagens, não System.Collections.Generic.List, específico para .NET. Isso foi pensado na criação do WCF, então há vários mecanismos para lidar com esse problema. ServiceContract e OperationContract são a primeira parte dessa equação, mas existem várias outras.
Vamos olhar a implementação de um serviço e comentar todos os aspectos que você precisa saber para o exame:
DataContract
Se você olhar para as classes AnswerSet, AnswerDetails, e TestQuestion, vai notar que todas elas têm o atributo DataContract. Esse atributo contém todas as informações sobre como os dados serão serializados.
Para a maioria dos casos, colocar esse atributo já será suficiente para sua classe ser serializada e desserializada pelo WCF e pelo client. Mas há algumas exceções:
- Se o item sendo enviado deriva de um DataContract, mas não é um DataContract;
- Se o tipo da informação transmitida for uma interface ou classe abstrata;
- Se o tipo for um Object.
Nesses 3 casos, geralmente haverá um erro na desserialização da classe. Para deixar a engine de serialização saber sobre um tipo, o atributo KnownType deve ser usado em conjunto com o DataContract.
Vamos ver um exemplo na prática. Suponha que você tenha uma classe base QuestionBase e as derivadas MathQuestion e EnglishQuestion:
[DataContract(Name="English" Namespace="487Samples")]
public class EnglishQuestion : QuestionBase
{}
[DataContract(Name="Math" Namespace="487Samples")]
public class MathQuestion : QuestionBase
{}
Agora suponha que você tenha a seguinte classe que deve ser serializada:
[DataContract(Namespace="487Sample")]
public class QuestionManager
{
[DataMember]
private Guid QuestionSetId;
[DataMember]
private QuestionBase ExamQuestion;
}
Por não saber quais os possíveis tipos para a classe abstrata QuestionBase, ao desserializar essa classe uma exception é lançada. Para resolver esse problema, como dito, o atributo KnownType deve ser usado para indicar quais tipos podem ser usados em uma QuestionBase:
[DataContract]
[KnownType(typeof(EnglishQuestion))]
[KnownType(typeof(MathQuestion))]
public class QuestionManager{}
Tirando as exceções acima, todos os tipos primitivos e algumas classes .NET são serializadas sem problemas pelo DataContractSerializer. A lista completa pode ser vista aqui.
A propriedade Name, não obrigatória, especifica um nome diferente da classe visível para os clients. AnswerSet, por exemplo, tem o Name Answers, e todos os clients enxergarão essa classe como Answers. A propriedade Namespace, também não obrigatória, serve para evitar conflitos de classes com o mesmo Name.
Além do atributo DataContract, é necessário colocar o atributo DataMember (ou EnumMember, no caso de um enum) em cada propriedade a ser serializada.
DataMember
DataMember indica uma propriedade a ser serializada. Se você marcar uma classe com DataContract mas nenhuma propriedade com DataMember, nada será serializado.
Há algumas propriedades opcionais que você pode setar:
- EmitDefaultValue: indica se, quando uma propriedade tiver o valor default, ela deve ser serializada ou não. O valor padrão é true. Deve ser marcada false para minimizar o tamanho da mensagem a ser serializada (dica para o exame);
- Name: identifica uma propriedade com um nome diferente para os clients;
- IsRequired: indica se a propriedade deve ter um valor ao serializar, resultando numa exception caso o valor seja default. O valor padrão é false;
- Order: especifica a ordem de serialização do membro;
- TypeId: caso definido numa classe derivada, retorna um identificador único para o atributo.
EnumMember
Funciona exatamente como DataMember, mas se aplica a enums. As propriedades opcionais são:
- Name: retorna o nome do membro;
- Value: retorna o valor do membro;
- BuiltInTypeKind: retorna o tipo;
- Documentation: obtém ou seta o objeto de documentação, se especificado.
O comportamento de Value é interessante. No caso do enum AnswerDetails, os valores serializados por padrão são A, B, C, D e All. Se você especificar o Value, esse valor será retornado no lugar. Por exemplo:
[DataContract(Namespace="http://www.williamgryan.mobi/Book/70-487")]
[Flags]
public enum AnswerDetails : int
{
[EnumMember(Value="1")]
A = 0x0,
[EnumMember(Value = "2")]
B = 0x1,
[EnumMember(Value = "3")]
C = 0x2,
[EnumMember(Value = "Bill")]
D = 0x4,
[EnumMember(Value = "Ryan")]
All = 0x8
}
FaultContracts
A classe base de exceções do .NET, System.Exception, não é conhecida por potenciais clients de um WCF, como Java ou Python. Cada framework tem sua maneira de lidar com exceptions, mas num cenário distribuído como o consumo de um serviço WCF, todos eles devem se comunicar igualmente tratando-se de erros. Outro problema frequente é que, em um cenário de exception, você provavelmente não gostaria de enviar todo o stack do erro para seus clients por vários motivos. FaultContracts resolvem esses dois problemas de maneira simples. Você pode definir quando e quais informações serão enviadas da exception sem expor seu serviço abertamente.
O método GetQuestionText mostrado anteriormente lançava uma exceção se o número da questão passado fosse igual ou menor a 0:
public String GetQuestionText(Int32 questionNumber)
{
if (questionNumber <= 0)
{
String OutOfRangeMessage = "Question Ids must be a positive value greater than 0";
IndexOutOfRangeException InvalidQuestionId = new IndexOutOfRangeException(OutOfRangeMessage);
throw new FaultException
}
String AnswerText = null;
// Method implementation
return AnswerText;
}
Para o client saber que uma exceção pode ser lançada por um serviço, isso deve estar definido no contrato do método:
[FaultContract(typeof(IndexOutOfRangeException))]
[OperationContract]
String GetQuestionText(Int32 questionNumber);
Com isso, exceções podem ser enviadas para o client sem problemas de compatibilidade. Se você quiser incluir detalhes sobre o erro, você pode setar a propriedade Reason que aceita um FaultReason.
FaultException tem outra propriedade chamada FaultCode. Com ela é possível especificar erros no nível de SOAP. SOAP 1.1, por exemplo, aceita os erros VersionMismatch, MustUnderstand, Client e Server. SOAP 1.2 provê os erros VersionMismatch, MustUnderstand, DataEncodingUnknown, Sender, e Receiver. Você deve levar em conta o binding do serviço, já que a especificação de mensagem de erro pode ser específico em SOAP 1.1 ou SOAP 1.2.
Ainda outra opção é usar a classe MessageFault, que te dá uma representação da falha em memória, o que permite que você especifique o erro o quanto quiser.
Para o exame, é recomendável se familiarizar com os construtores da classe FaultException. São eles:
- FaultException(): cria uma FaultException;
- FaultException(FaultReason): cria e especifica uma Reason;
- FaultException(MessageFault): cria e especifica uma MessageFault;
- FaultException(String): cria e usa a string para criar uma FaultReason com o texto;
- FaultException(FaultReason, FaultCode): cria especificando uma FaultReason e um FaultCode;
- FaultException(MessageFault, String): cria especificando uma MessageFault e uma string para a action SOAP fault;
- FaultException(SerializationInfo, StreamingContext): cria especificando informações de serialização e um contexto em que a FaultException será desserializada. Pouco provável de ter no exame;
- FaultException(String, FaultCode): cria especificando uma FaultReason e um FaultCode;
- FaultException(FaultReason, FaultCode, String): cria especificando uma FaultReason, um FaultCode e uma string para a action SOAP fault;
- FaultException(String, FaultCode, String): o mesmo que o anterior, mas a primeira string é transformada em uma FaultReason.
Resumindo, foque em como definir um FaultContract, como lançar uma FaultException e as principais propriedades dela (FaultReason e FaultCode). Tenha em mente também que FaultException herda de CommunicationException.
Implementando Inspectors
Você pode implementar inspectors que estendem o comportamento do WCF.
O primeiro deles é o Parameter Inspector. Com a interface IParameterInspector você consegue validar se os parâmetros atendem à condições customizadas antes que o serviço seja de fato chamado. Por exemplo, se um serviço recebe um parâmetro userName e este deve ser o tamanho maior que 7, um Parameter Inspector poderia ser implementado para evitar chamadas desnecessárias ao serviço.
A interface IParameterInspector tem dois métodos bem intuitivos: BeforeCall e AfterCall. No exemplo acima, fica claro que nossa lógica precisa estar em BeforeCall.
O client precisa ter uma referência à classe que implementa IParameterInspector e adicionar na coleção Behaviors da propriedade Operations da classe proxy:
ProxyInstance.Endpoint.Contract.Operations[0].Behaviors.Add(new UserNameInspector());
Feito isso, é necessário criar o atributo (que herda de Attribute e IOperationBehavior) a ser inserido no contrato e a classe que implementa a interface IParameterInspector:
Outro inspector é o Message Inspector. O propósito dele é você interceptar processamentos dado algum evento. Digamos que seu serviço processa uma compra de um e-commerce. Você dispara uma verificação do cartão de crédito informado e inicia o processamento de salvar todos os dados. No meio do processamento, a operadora do cartão de crédito retornou que este é inválido. Com um Message Inspector, você conseguiria interromper e cancelar o processo que estava ocorrendo de salvar todas as informações.
Para implementar um Message Inspector do lado do server, você usa a interface IDispatchMessageInspector. Ela possui dois métodos:
- AfterReceiveRequest: chamado após receber um request, mas antes da mensagem ser encaminhada para o método;
- BeforeSendReply: chamado após o retorno do método mas antes que o retorno seja enviado de fato para o client.
Uma vantagem do Message Inspector é que você o adiciona no pipeline do WCF via arquivo de configuração, evitando que o serviço inteiro seja deployado para que um inspector seja adicionado. Assumindo que a classe ServerInspector implementa a interface IDispatchMessageInspector, você o habilita com a seguinte configuração:
<extensions>
<behaviorExtensions>
<add name="clientSample" type="Samples.WCF.Services.ServerInspector, ClientHost, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null"/>
</behaviorExtensions>
</extensions>
É possível implementar Message Inspectors do lado do client também, de forma bem parecida com a do server. A interface responsável se chama IClientMessageInspector e tem os seguintes métodos:
- BeforeSendRequest: chamado antes de um request ser enviado ao serviço;
- AfterReceiveReply: chamado após o response do server, mas antes de ser encaminhado ao método que o chamou.
Para adicioná-lo no WCF, a configuração é exatamente igual à do server. Para o exame você deve saber que MessageInspectors existem, quais interfaces devem ser implementadas e onde especificá-los no arquivo de configuração.
A finalmente terminamos 🙂
Fique ligado no post do próximo objetivo, Configure WCF services by using configuration settings.
Até mais!