Olá!
O objetivo 2.5 da certificação, Create an Entity Framework data model, é o último objetivo do segundo tópico da certificação, Querying and manipulating data by using the Entity Framework. Finalmente vamos ver como construir um Entity Model, além de recordar alguns conceitos e componentes do EF cobertos no objetivo 1.1.
Esse objetivo cobre como: 1) estruturar o model usando as heranças Table-per-Type e Table-per-Hierarchy, 2) escolher e implementar um método de data model (Model First ou Database First), 3) implementar objetos POCO e 4) descrever um data model usando Conceptual Schema Definitions, Storage Schema Definition, e Mapping Language (CSDL, SSDL, MSL). Vamos lá?
Estruturando o Data Model Usando as Heranças Table-per-Type e Table-per-Hierarchy
Você pode tratar os casos de herança de duas formas: Table-per-Type (tabela por tipo) e Table-per-Hierarchy (tabela por hierarquia).
Basicamente, a diferença entre as duas é que, em tabela por tipo, cada classe herdeira vira uma tabela no banco de dados. Em tabela por hierarquia, tanto a classe pai quanto as filhas ficarão guardadas na mesma tabela, geralmente com uma coluna indicando qual é o tipo.
Para o exame, você deve saber quais são as vantagens e desvantagens das duas formas:
Tabela Por Tipo
Vantagens:
- Os dados não são guardados redundantemente;
- Os dados são armazenados na terceira norma formal, aumentando a integridade;
- A implementação é mais simples. Para adicionar ou remover uma entidade herdeira, basta deletar a tabela no banco de dados e atualizar o Entity Model.
Desvantagens:
- A performance é afetada em operações básicas (CRUD);
- Complica a administração do banco de dados pelas tabelas adicionais.
Tabela Por Hierarquia
Vantagens:
- Deixa o schema do banco simplificado por conter menos tabelas;
- Operações de CRUD otimizadas por trabalhar em uma só tabela.
Desvantagens:
- Há redundância dos dados por não seguir a terceira normal formal;
- Pode haver problemas com a integridade dos dados devido a redundância;
- O Entity Model fica mais complexo pela tabela conter mais campos.
Escolher e Implementar um Método de Data Model (Model First ou Database First)
Escolher um modelo de EDM é um conceito importante, mas não há muito o que aprender aqui.
Model First acontece quando você cria um modelo vazio e vai criando os recursos necessários, como as entidades, os relacionamentos entre elas e o comportamento das propriedades. Depois disso tudo, você gera o schema do banco de dados do EDM; e o Entity Framework cuida da criação do banco de dados e o mapeamento entre o banco e o modelo.
Database First, como esperado, assume que você já tem o schema do banco de dados pronto e escolhe criar o EDM a partir dele. Nesse caso, o Entity Framework cuida da criação dos itens do EDM e o mapeamento entre eles.
Outro ponto importante nesse assunto são as propriedades que você pode setar diretamente no EDM, escolhendo qualquer um dos dois métodos. Clicando com o botão direito no designer e indo em Properties, você pode controlar algumas propriedades que têm o nome bem sugestivo, como se o Lazy Loading deve ser utilizado, o nome do namespace desejado, o nível de acesso dos containers, etc.
Indo nas propriedades de cada entidade ou em alguma propriedade, há alguns comportamentos e configurações que podem ser alterados:
- A classe base da entidade;
- Se a propriedade é Nullable;
- Visibilidade dos getters e setters;
- Um valor default para uma propriedade;
- Essa é bem interessante: a propriedade Concurrency Mode, quando setada para Fixed, assegura que o valor no banco de dados não foi alterado quando você vai atualizá-lo. Por exemplo, se você obteve uma entidade do banco com uma propriedade no valor “x” e vai alterá-la para “y”, o Entity Framework vai validar se o valor ainda é “x” antes de você atualizá-lo para “y”. Isso pode ser bem útil em alguns cenários, mas carrega uma piora na performance pela validação. Outro ponto é que, embora esse comportamento seja definido no nível de propriedade, se você tiver 50 campos setados para Fixed, apenas uma query será feita no banco para comparar os 50 valores.
Implementar Objetos POCO
Ao criar uma entidade no EDM, o Entity Framework vai gerar a classe .NET automaticamente. Caso desejado, você pode desabilitar esse comportamento nas Properties do designer e criar você mesmo um POCO (plain old common object), tendo mais controle sobre suas classes.
Para usar suas classes POCO no contexto do EF, alguns passos são necessários. A primeira coisa é que as classes devem ser decoradas com o atributo Table, especificando o nome da tabela no banco de dados:
[Table("Account")]
public class Account{}
[Table("Customers")]
public class Customers{}
[Table("TransactionDetails")]
public class TransactionDetail{}
Table("Transactions")]
public class Transaction{}
O modo de vincular as classes no contexto depende se você estiver utilizando DbContext ou ObjectContext.
Com DbContext, basta definir as classes usando a classe genérica DbSet e passando o tipo de cada POCO:
public partial class EntityFrameworkSamplesEntitiesDb : DbContext
{
public EntityFrameworkSamplesEntitiesDb(): base("name=EntityFrameworkSamplesEntities1")
{}
public DbSet
public DbSet
public DbSet
public DbSet
}
Com ObjectContext não é muito diferente. A classe genérica ObjectSet deve ser usada e as propriedades devem ser inicializadas no construtor:
public partial class EntityFrameworkSamplesEntitiesSample : ObjectContext
{
public EntityFrameworkSamplesEntitiesSample(): base("name=EntityFrameworkSamplesEntities1")
{
Accounts = new ObjectSet
Customers = new ObjectSet
TransactionDetails = new ObjectSet
Transactions = new ObjectSet
}
public ObjectSet
public ObjectSet
public ObjectSet
public ObjectSet
}
Descrever um Data Model Usando Conceptual Schema Definitions, Storage Schema Definition, e Mapping Language (CSDL, SSDL, MSL)
O Entity Framework junta cada um desses componentes no arquivo .edmx, mas para o exame é importante entender qual o papel de cada um. Basicamente, o CSDL é o conceito do schema do banco traduzido para objetos; o SSDL representa o próprio schema do banco de dados e o MSL é o responsável por juntar os dois e mapear o schema do banco com os objetos.
Não há muito o que ir mais fundo sobre o CSDL e o SSDL, a não ser que são XMLs representando informações – objetos e modelos relacionais de banco de dados. O MSL, que unifica os dois, é um pouco mais complexo e merece um entendimento maior.
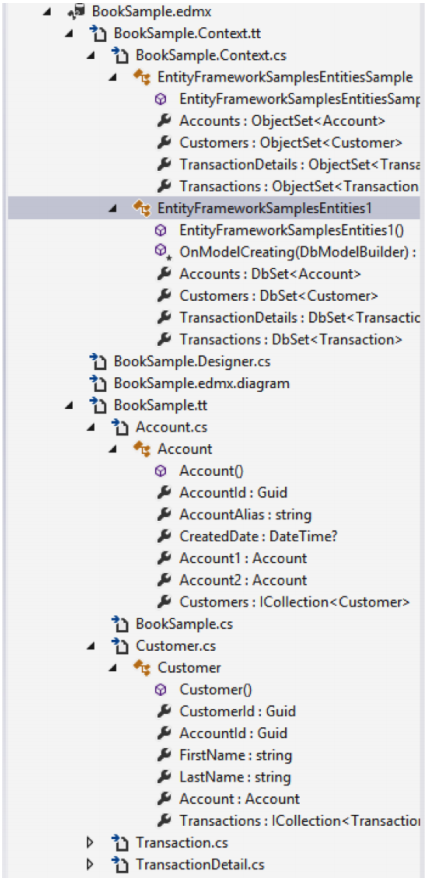
O MSL, junto com o .edmx, contém vários outros arquivos gerados automaticamente. São eles:
- Um arquivo .edmx que serve como container para tudo;
- Um arquivo ModelName.Context.tt para geração de templates das classes .NET especificadas no model do respectivo contexto;
- O arquivo ModelName.Context.cs que contém as classes do contexto;
- O arquivo ModelName.Designer.cs que provê suporte para o designer do EDM;
- Um arquivo ModelName.edmx.Diagram que contém um XML parecido com o seguinte:
<?xml version="1.0" encoding="utf-8"?>
<edmx:Edmx Version="2.0" xmlns:edmx="http://schemas.microsoft.com/ado/2008/10/edmx">
<!-- EF Designer content (DO NOT EDIT MANUALLY BELOW HERE) -->
<edmx:Designer xmlns="http://schemas.microsoft.com/ado/2008/10/edmx">
<!-- Diagram content (shape and connector positions) -->
<edmx:Diagrams>
<Diagram DiagramId="8576b1de6991436caba647ac89886831" Name="Diagram1">
<EntityTypeShape EntityType="EntityFrameworkSamplesModel1.Account" Width="1.5" PointX="7.5" PointY="0.875" IsExpanded="true" />
<EntityTypeShape EntityType="EntityFrameworkSamplesModel1.Customer" Width="1.5" PointX="9.75" PointY="0.875" IsExpanded="true" />
<EntityTypeShape EntityType="EntityFrameworkSamplesModel1.TransactionDetail" Width="1.5" PointX="14.25" PointY="0.875" IsExpanded="true" />
<EntityTypeShape EntityType="EntityFrameworkSamplesModel1.Transaction" Width="1.5" PointX="12" PointY="0.875" IsExpanded="true" />
<AssociationConnector Association="EntityFrameworkSamplesModel1.FK_Account_Account" ManuallyRouted="false" />
<AssociationConnector Association="EntityFrameworkSamplesModel1.FK_Customer_Account" ManuallyRouted="false" />
<AssociationConnector Association="EntityFrameworkSamplesModel1.FK_Transactions_Customer" ManuallyRouted="false" />
<AssociationConnector Association="EntityFrameworkSamplesModel1.FK_TransactionDetails_Transactions" ManuallyRouted="false" />
</Diagram>
</edmx:Diagrams>
</edmx:Designer>
</edmx:Edmx> - Por último, o arquivo ModelName.tt que tem as informações de template para geração das classes de dados.
Uma olhada no arquivo .edmx pode ajudar na visualização de todos esses artefatos:
Isso é tudo para esse objetivo. O próximo post cobrirá o primeiro objetivo do capítulo 3 da certificação, Designing and implementing WCF Services.
Nos vemos lá!